

Dieser Leitfaden zeigt, wie Sie jede Gesangsvoreinstellung schnell und vorhersehbar an Ihre Stimme anpassen: Eingang einstellen, Klang formen, Steuerung justieren und Raum platzieren, der auf Ohrhörer, Lautsprecher und das Auto übertragbar ist.
I. Beginnen Sie mit Ihrem „Stimmenabdruck“
Ihre Stimme hat einen wiedererkennbaren Fingerabdruck: Helligkeit, Zischlaute, Dichte und transiente Schärfe. Identifizieren Sie diese Merkmale zuerst und passen Sie dann die Voreinstellung entsprechend an.
- Helligkeit: Funkeln oder stechen Ihre S-Laute? Hören Sie mit Ohrhörern.
- Dichte: Dünn vs. voll bei niedrigen Lautstärken.
- Transientenbiss: Plosive und Konsonanten, die hervorstechen.
- Raumentdeckung: Nachhall, Flattern oder tiefer Rumpelton.
Begriffe, kurz: dBFS ist das digitale Pegelmaß (0 dBFS übersteuert). LUFS ist die wahrgenommene Lautheit. True Peak (dBTP) schätzt Inter-Sample-Spitzen, die Wandler übersteuern können.
II. Anpassungskarte (Charakter → Anpassung zuordnen)
| Stimmcharakteristik | Was du hörst | Preset-Anpassungen |
|---|---|---|
| Hell / zischend | S-Laute stechen, Becken konkurrieren | De-Esser zuerst in der Kette (5–8 kHz, breit); High-Shelf um −1 dB reduzieren |
| Dunkel / verhangen | Wörter klingen dumpf in vollen Hooks | Sanfte Präsenz +1 dB bei 3–4 kHz; langsamere Release-Zeit bei Komp 1 |
| Dünn / luftig | Fühlt sich bei niedriger Lautstärke klein an | Low-Mid-Unterstützung +1–2 dB bei 160–220 Hz; parallele Kompression 10–20% |
| Dröhnend / matschig | Kicks kämpfen mit dem Gesang | Hochpass 80–100 Hz; schmaler Schnitt 200–350 Hz |
| Harte Konsonanten | T, K, P stechen hervor | Längerer Attack bei Kompressor 1; Transient Shaper Sustain −5–10% |
| Raumig / reflektiv | Flattern und Klingeln | Näheres Mikro + Popfilter; Gate/Expander leicht; kürzere Hall-Ausklangzeit |
III. Schnell-Anpassungs-Workflow (8 verlässliche Schritte)
- Sauber trimmen. Laut aufnehmen, dann Eingang so einstellen, dass Spitzen bei etwa −12 bis −8 dBFS liegen.
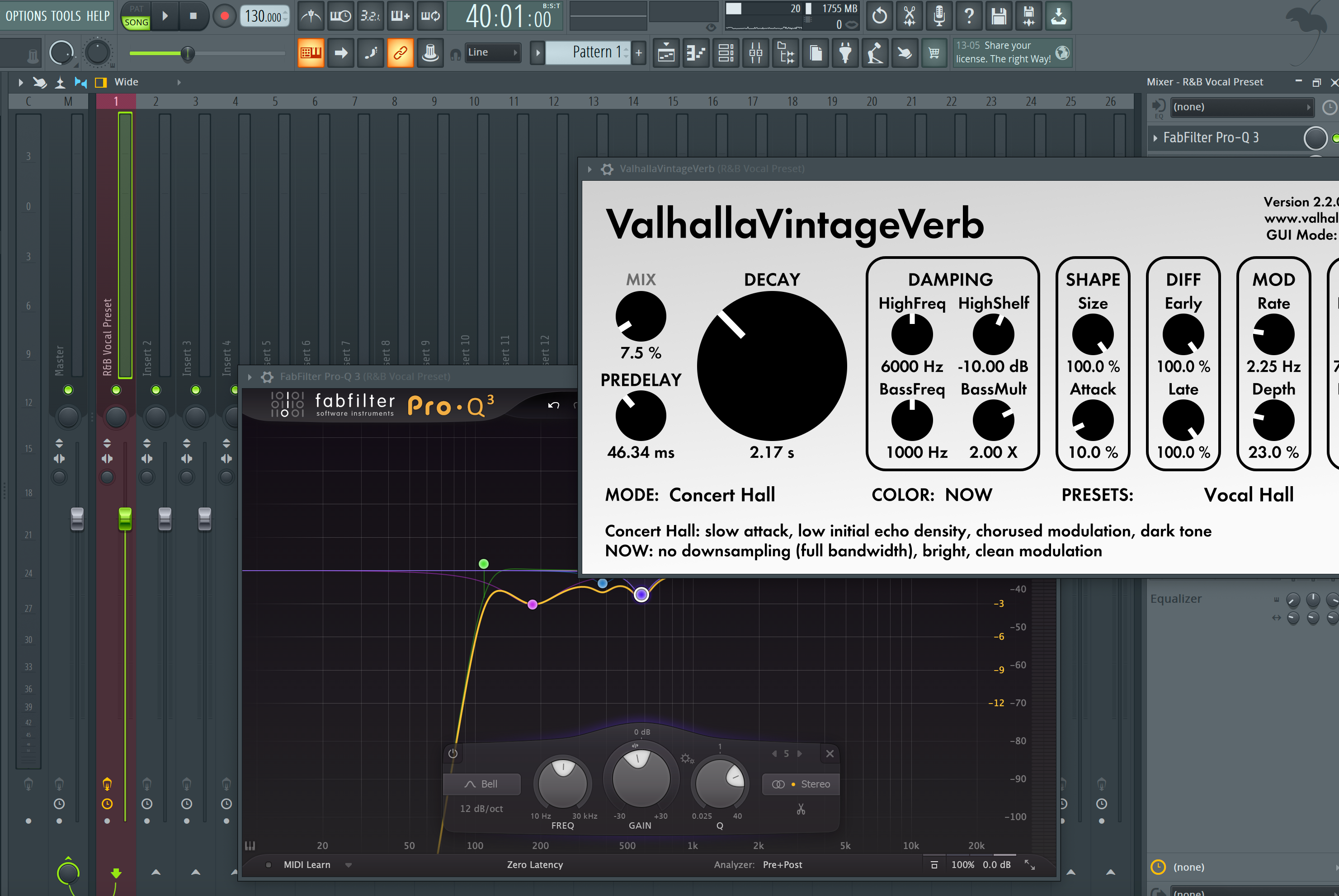
- De-esser früh platzieren. Breites Band bei 5–8 kHz vor jeglichen Excitern oder Tape-Stufen.
- Schlamm abschneiden, nicht zuerst anheben. Hochpass, dann eine entschiedene Kerbe gegen Boxigkeit.
- Verankere mit Kompressor 1. Ziel 3–6 dB Gain-Reduktion; Ausklingzeit so einstellen, dass sie bis zum nächsten Wort entspannt.
- Füge Farbe mit Zurückhaltung hinzu. Sättigung für Dichte; Ausgang pegeln, damit „lauter“ dich nicht täuscht.
- Führe den Handschlag mit dem Beat. Kleiner dynamischer EQ auf dem Gesang oder Sidechain ein schmales Absenken nur auf dem Beat, wenn du singst.
- Timing für deinen Raum. Delay 1/8 oder 1/4; Hall-Vorverzögerung 20–60 ms; Sends nach Abschnitt automatisieren.
- Spitzen sanft abfangen. Schneller zweiter Kompressor oder Limiter, der 1–2 dB küsst; Bypass innerhalb von 0,5 dB erneut prüfen.
IV. Kontextabhängige Anpassung (schnelle Rezepte)
Über einem hellen 2-Spur-Mix. Hochtonregler um −1 dB absenken, De-esser-Band verbreitern und eine dunklere Plate ausprobieren. Wenn Becken im Bereich 6–8 kHz drängen, den S-Fokus etwas höher setzen.
Pop-Duett oder geschichtete Harmonien. Hochpassstapel höher, De-esser stärker als beim Lead, und Sättigung niedriger halten, damit der Lead den Glanz behält.
R&B-Ballade. Längere Vorverzögerung (40–60 ms), langsamere Ausklingzeit bei Kompressor 1 und ein subtiler 1/8-Noten-Echo für mehr Tiefe.
Aggressiver Rap. Kürzere Ausklingzeit, minimaler Hall, straffer Slapback. Wenn Konsonanten knallen, den Attack etwas verlängern.
V. Mikro-Probleme → Mikro-Lösungen
- Wörter verschwinden im Refrain: +1 dB bei 2–3 kHz oder Delay-Send erhöhen; Hallfahne verkürzen.
- S-Laute springen auf Kopfhörern hervor: De-ess-Bereich erweitern; High-Shelf um −0,5 bis −1 dB absenken.
- Gesang vs. Bass kämpfen: Hochpass um ein paar Hz anheben; dynamisches Absenken des Basses bei 120–180 Hz, getriggert vom Gesang.
- Preset wirkt überkomprimiert: Ratio senken oder parallel 10–20 % mischen statt Inserts zu zermalmen.
- Atemgeräusche zu laut: Post-Chain Clip-Gain bei Atemzügen um −2 dB senken; Wörter nicht gate.
VI. Mach es portabel (einmal speichern, schnell anpassen)
Speichere eine Basis für deine Stimme. Benenne sie „DeinName_Base (Peaks −10 dBFS)“. Zukünftige Sessions benötigen nur Eingangs-Trim, eine EQ-Änderung und Sends.
Trenne Tonhöhe vom Klang. Halte starke Tonhöhenkorrektur auf einer eigenen Spur. Doubles und Harmonien brauchen selten identische Abstimmung.
Dokumentiere die Sweet-Spots. Füge Notizen hinzu: HPF-Wert, Kompressor 1 Release-Zeit, De-ess-Band. Das wird dein persönliches Recall-Blatt.
VII. FAQs
Soll ich beim Gesang eine LUFS-Zahl anstreben?
Nein. Lautstärkeziele gehören zum Gesamtmix. Halte den Gesang kontrolliert und natürlich.
Wo sollte das De-essing sitzen?
Normalerweise vor der Klangfärbung. Wenn S-Laute noch hervorstechen, füge später ein leichteres zweites De-essing hinzu.
Kann ein Preset genresübergreifend funktionieren?
Ja – wenn du die wenigen oben genannten Schritte anpasst. Die meisten Änderungen liegen bei 1–2 dB, keine kompletten Neuschreibungen.
Warum bricht das Preset im Auto zusammen?
Die Wiedergabe im Auto betont 2–4 kHz. Überprüfe Präsenz und De-essing-Balance erneut und verifiziere dann bei angepasster Lautstärke.
Fazit
Das Anpassen eines Presets an deine Stimme geht schnell, sobald du weißt, worauf du hören musst. Schneide, zähme, forme und timiere deinen Raum – und speichere dann das Ergebnis. Wenn du Ketten für gängige Stimmtypen und DAWs suchst, erkunde die kuratierte Vocal Presets-Kollektion und personalisiere die letzten 10 % für deine Aufnahme.








